23andMe가 보여준 희망 - 당연하지만 아무도 성공하지 못했던...
당연하지만 아무도 성공하지 못했던 것은 유전형-표현형간 연결입니다. 대량의 데이터를 이용한. 누구나 이걸 하면 성공할 거라고 생각했는데 23andMe가 정말 잘 풀어내서 결국 신약개발까지 이어가고 있습니다.
최근 23andMe에서 스페인의 Almirall사에 IL-36 (면역관련 체내 단백질) 을 타겟으로 하는 자가면역질환 약물을 라이센스 아웃했다는 소식을 들었습니다. pre-clinical까지 끝내고 임상 1상부터 개발 및 전세계 상업화 판권을 넘겼다고 하네요.

저는 23andMe의 데이터에 대해 편견을 갖고 있었습니다. 귀지의 형상이나 눈동자 색깔 따위를 알려주는 그런 서비스가 어떤 임상적 결과를 낼 수 있을지 의심하고 있었지요. 그만큼 이번 라이센스 아웃 소식은 제게 신선하게 다가왔습니다.
23andMe는 다음과 같은 서비스를 제공하여 소비자들에게 정보를 제공하며, 이러한 정보들을 축적하여 연구에 사용할 수 있도록 동의를 받습니다. Ancestry은 가계 (인종) 정보, Health Predisposition은 질환 예측 인자 정보, Carrier는 발병인자 정보를 제공하는 동시에 23andMe의 database로 축적될 것입니다.

23andMe가 이러한 데이터를 활용하여 신약개발을 위한 의미있는 연구를 진행하고 있다는 것은 지난 GSK와의 계약을 통해서도 알 수 있었습니다. GSK는 지난 2018년 23andMe에 3억달러를 지급하고 23andMe의 DB에 접근하여 연구할 수 있는 권한을 얻었습니다. (https://www.gsk.com/en-gb/media/press-releases/gsk-and-23andme-sign-agreement-to-leverage-genetic-insights-for-the-development-of-novel-medicines/) 당시 GSK에서는 Parkinson's disease 대상 후보물질인 LRRK2 inhibitor개발에 이 DB를 활용할거라고 하였습니다.
그럼에도 불구하고 당시에는 early stage의 파이프라인에 대해 연구한다는 내용이었기 때문에 drug discovery에 일부분 도움이 될 뿐 임상단계에서 실질적인 연구로 진행될지 더 지켜보아야 한다는 생각이었습니다. (제 옹졸한 생각)
제가 의심을 가졌던 이유는 다음과 같은 이유 때문입니다. 23andMe의 데이터가 당연히 Garbage는 아니나, 이를 통해 약을 개발할 정도의 정교한 drug target을 밝히기에는 두가지가 부족하다고 생각했습니다. 1) 유전체 데이터라고 보기에는 데이터가 부족하고 2) 환자들의 survey data를 '표현형(Phenotype)'으로 취급하고 연구를 진행하기에는 그 응답을 믿기가 어렵다고 믿었습니다. (잘못된 믿음이었던 것 같습니다. 생각해보면 뛰어난 박사님들이 모이셨는데 어련히 알아서 하셨을까...)
데이터가 부족하다는 이유는 23andMe가 복잡한 질병의 정보를 단순한 microarray 검사를 통해 알아내려고 했기 때문입니다. microarry가 찾아내는 것은 유전자상의 gene variant고작 몇만개인데 30억개에 달하는 유전자쌍과 그 상호작용, 유전자 이후 단백질 발현까지 transcription, translation, post-translational modification으로 이어지는 단계를 고려하면 23andMe의 유전자 검사로 볼 수 있는 범위가 너무 적고 개별 variant가 질병 발현에 기여하는 정도가 너무 적다고 생각했습니다.
그런데, 그동안 23andMe는 연구를 통해 임상적인 관련성이 제안된 variant의 정보를 많은 샘플로부터 수집하여 이 문제를 해겨하기위한 단계를 밟아왔던 것 같습니다. SNPedia (공개 데이터베이스로, 연구자들이 공개한 genotype에 대한 정보 - 유전자 상 위치, 관련 표현형, 관련 출판물 등 - 를 제공)에 따르면, 23andMe는 현재 약 24K개의 SNP을 검사할 수 있는 플랫폼을 사용하고 있습니다. 2008년부터 플랫폼이 달라지기는 했어도 검사 대상 변이 수를 크게 바꾸지는 않았었네요. SNPedia만 알려진 11만개 SNP이 있다는데 이중에 임상적으로 의미가 있을만 한 SNP만 2만4천개 사용하겠다는 생각이로군요.
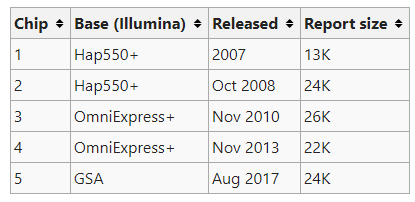
이 2만 4천개에 대해 2019년 4월 기준 1000만개의 샘플을 보유하고 있다니.. Ancestry.com보다는 적으나 health관련 정보를 제공하는 업체로는 독보적이네요. (Ancestry.com이 미국에서는 광고도 많이하고 잘나갑니다)

두번째로 환자들의 survey data를 표현형으로 받아들이기 어렵다고 생각했습니다. 그런데...

survey는 무려 300개 문항까지 제시될 수 있다네요. 저한테는 지금 15개밖에 없는데, 대답을 할수록 그에 맞는 다른 문항들이 제공된다 합니다. 기본적인 Health survey에서는 흔한 건강검진 문항 정도가 제공되는데 어떤 질병이 있다고 하면 그에 대한 발현/치료/경과에 대한 자세한 정보 획득을 위한 추가 survey가 제공되는 것 같습니다. 이러한 구조화된 survey는 비록 임상연구에서 연구자의 개입에 의해 quality control이 되는 정보보다는 질이 낮겠지만 많은 수가 모이면서 효과를 보이게 될 것 같습니다. 전체 서비스 대상자 중 약 30%정도가 survey를 완료한다고 하는데, 현재 1,200만명에게 서비스를 제공하였다고 하니 약 360만명이 survey를 수행했다고 볼 수 있습니다. 유전자 변이 데이터와 잘 연결된 구조화된 임상정보데이터라니 단순히 1000만명 유전자를 모았다와는 차원이 다른 이야기입니다.
2019년에 출간된 논문인 "Phenotypic analysis of 23andMe survey data: Treatment-resistant depression from participants' perspective"에 따르면 56,000명의 depression환자가 survey (Antidepressant Efficacy Questionnaires, AEQ)를 진행하였고, 이들에 대해서는 질병의 소인, 증상의 표현형, 약물복용여부, 경과 등에 대한 자세한 sruvey가 수행되었습니다. Harvard Medical School의 교수님께서 직접 개발하셨다고 기재되어있네요. 기존 임상연구에서 사용되는 구조화된 설문일 것 임을 추측할 수 있습니다. Discussion에서 설문이 prior knowledge와 일치하는 결과를 보인다며 신뢰도있는 설문이었음을 이야기하네요.
("Despite the large number of predictors tested, most of the statistical tests were significant even after adjusting for multiple testing correction, which to some extent could be attributed to the large sample size and the hypotheses tested were based on prior knowledge. However, the direction of association between question and TRD status was consistent with what would be hypothesized.")
이외에도 23andMe는 여러 연구에서 환자 대상의 survey data로 유전형에 의한 표현형을 밝힐 수 있음, 즉 표현형을 정확히 얻어낼 수 있음을 밝혀왔습니다. 2015년 White paper (Genetic Associations with Traits in 23andMe Customers, Saniya Fayzullina et al, 2015, accessed at https://objects.23andme.com/res/pdf/eEK9zpYQRGYVvUXuEd0VQw_23-08_Genetic_Associations_With_Traits.pdf) 에서는 고수 맛을 버티는 사람인지, 단맛/신맛 선호가 어떠한지, 껌씹는 소리에 민감한 정도가 어떠한지 등을 survey data와 유전자 검사로 밝혀냈음을 말하고 있네요. Motion sickness관련 유전자 변이를 찾은 2015년 논문 (Hromatka, Bethann S., et al. "Genetic variants associated with motion sickness point to roles for inner ear development, neurological processes and glucose homeostasis." Human molecular genetics 24.9 (2015): 2700-2708.)도 보입니다.
23andMe의 단순한 유전자 검사 데이터도 그 큰 수로 인해 의미가 있고, survey data도 허투로 보아서는 안된다는 말씀입니다. 반성합니다.
이러한 방식으로 질병에 연관된 유전자를 잘 찾아낸다면, 이 유전자 혹은 유전자가 코딩하는 단백질/RNA, 연관 단백질 등을 target하는 방식으로 신약개발을 쉽게(?) 해낼 수 있을 겁니다. 아래 그림은 'Accelerating drug development with 23andMe phenome-wide association studies'라는 포스터에 삽입된 개념도입니다. (https://objects.23andme.com/res/permalink/pdf/ashg/23andMe_ASHG14_DrugDevelopment.pdf)
간단히 이야기하면 23andMe의 유전자검사 데이터와 survey data를 연결시켜 만든 gene-disease연관관계가 기존에 출시된 약들과도 잘 맞더라.. 입니다.

이런 방식을 통해 2017년에는 allergy와 관련된 유전자 변이를 찾은 논문 (Ferreira, Manuel AR, et al. "Eleven loci with new reproducible genetic associations with allergic disease risk." Journal of Allergy and Clinical Immunology 143.2 (2019): 691-699.)을 발표하였습니다. 낮은 질병 위험도와 관련된 4개 gene을 발견하였고, 이를 억제하는 약물이 allergic disease를 치료할 수 있을거라는 가설을 제시하였네요. 2019년에는 Parkinson's disease와 관련된 논문(Whiffin, Nicola, et al. "Human loss-of-function variants suggest that partial LRRK2 inhibition is a safe therapeutic strategy for Parkinson’s disease." BioRxiv (2019): 561472.) 또 varicose vein의 치료하기 위한 drug target도 제안하였네요 (Wiberg, Akira, et al. "Genome-wide association analysis and replication in 810,625 individuals identifies novel therapeutic targets for varicose veins." BioRxiv (2020))
2017년 이후 최근에 발표되는 논문들은 이전에 발표된 내용에 비해 더 적극적으로 drug target에 대해 이야기하고 있음을 알 수 있습니다. 2019년 8월 USPTO에 제출된 약물에 대한 물질특허까지 찾아볼 수 있었습니다. Interleukin inhibitor를 자가면역질환 치료를 위한 신약물질로 제시하고 있습니다.

결론적으로, 23andMe는 설립초기 보여주었던 비전을 실현해나가고 있습니다. 23andMe가 갖고 있는 요소기술들은 대단한 것들은 아닙니다. 앞서 보여드린 바와 같이 Microarray는 대중화(?)된 검사법이고, 환자로부터 얻는 데이터래봤자 고도의 전문가가 개입되지 않은 웹 기반 설문조사일 뿐입니다. 23andMe가 써내려가고 있는 성공은 전적으로 이 두 데이터 간의 연결 때문이라고 생각합니다. (데이터의 연결 및 분석에 대한 기술도 쉽지 않을 터이나 두가지 raw data의 확보 및 연결관계 구축이 가장 어려운 rate-limiting step이라고 생각합니다.) 특히 표현형에 관련하여 수만명으로부터 구조화된 데이터를 얻어내는 것은 정말 힘든 일입니다. research목적의 동의 라는 울타리에서 개인정보 보호의 벽까지 스마트하게 넘어버렸죠.
데이터가 쌓일수록 23andMe의 성과는 점점 높아질 것입니다. 23andMe발 희소식도 계속해서 들려오리라 예상합니다. 결국 신약 출시까지는 또다른 10년이 남았겠지만 이정도까지만 해도 충분히 유전자정보활용의 가능성을 보여준 것이라고 생각합니다. 이러한 추세가 지속되어, 신약개발을 둘러싼 informatics의 발전과 규제기관의 paradigm shift가 동반되어 신약개발 비용절감 및 효율화를 기대해봅니다.